艳照门事件完整视频 企业数据经管果然幻梦成空? 4 大计谋 + 3 种秩序手把手教你拆解!

数字化时间,数据不错说是如同企业的血液。研究词,不准确、不圆善、不一致的数据却让企业的运营处处受阻。许多企业首先的起点是好的,想要降本增效,示寂呢艳照门事件完整视频,是降本增笑。企业怎么能从海量数据中找到准确的信息而幸免耗尽大皆时期和元气心灵?又怎么能幸免数据交集而导致的决策失实?
谜底是——数据清洗。通俗来说,数据清洗即是对数据进行审查和校验的过程,主义是删除雷同讯息、立异存在的差错,并提供数据一致性。如何灵验进行数据清洗,走好数字化转型的每一步,是企业要念念考的紧迫命题。
先给大家共享一份《数据仓库设立有蓄意》,包含了数仓的时期架构、数仓设立错误动作、数仓载体/器具、确立参考、大数据场景守旧案例等内容,限时免费下载!
https://s.fanruan.com/gp9fn
一、数据清洗的意念念.
家喻户晓,在数据分析敷陈中,未经清洗的数据很可能会导致差错的论断,裁减敷陈的确切度。而通过数据清洗,就不错去除差错、冗余或不圆善的数据,进步数据分析的准确性。
四肢预处理的紧迫要津,数据清洗在各个领域皆有着平常的应用:
(1)关于建立数据仓库,当多个数据库合并或多个数据源集成时,需要进行数据清洗。数据清洗包括数据的清洗和结构退换两个过程,为数据仓库的高效运行提供保险。
(2)在机器学习和东谈主工智能领域,数据清洗的作用主要体刻下数据相聚、清洗、预处理、存储和分析等方面。通过数据清洗处理不圆善、差错或雷同的数据,为模子清闲提供高质料的数据。
二、常见的数据清洗问题及处理秩序
其实,数据清洗四肢数据处理的一部分,不是通俗的过程,而是会靠近多样各种的问题,这里给大家列举几个常见的数据清洗问题,并给出相应的处理秩序,但愿对大家有所匡助!
(一)缺失值处理
1. 识别缺失值的秩序
热图可视化是一种灵验的识别缺失值的秩序。通过将数据以热图的状态展示,不错直不雅地看出哪些数据点存在缺失。脸色的浅深不错代表数据的圆善性进程,脸色越浅示意缺失值越多。比如下图即是数据可视化热图:
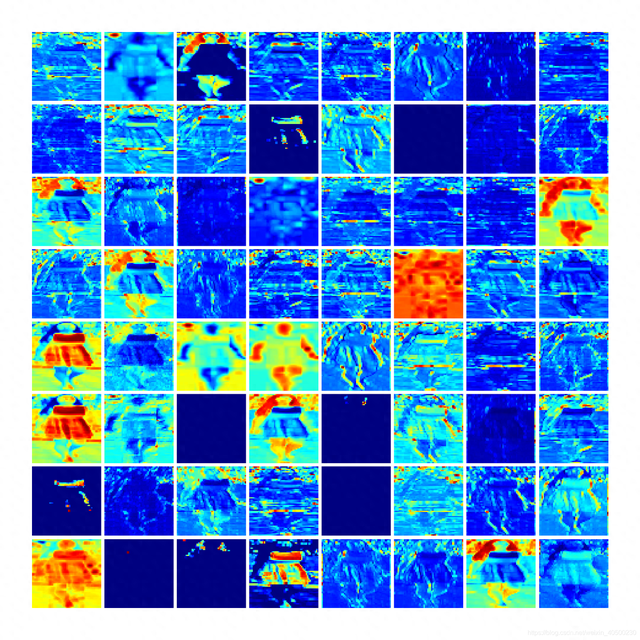
列出缺失数据百分比亦然一种常见的秩序。不错计较每个字段的缺失值比例,举例,假定有一个包含 1000 札记载的数据集,某个字段有 200 札记载存在缺失,那么该字段的缺失数据百分比为 20%。
缺失数据直方图不错匡助咱们更直不雅地了解数据的缺失情况。将数据鸠集的缺失值数目以直方图的状态展示,不错了了地看出不同字段的缺失值散播情况。比如不才图展示的缺失数据直方图中。
2. 处理缺失值的计谋
丢弃不雅察值是一种处理缺失值的秩序。在丢弃不雅察值时,咱们一般要温顺两个条款:一是缺失值数目较少;二是缺失数据对举座数据影响较小,是以,这就要求咱们设立“大局不雅念”,从数据的举座大局启航。举例,在一个包含 1000 札记载的数据集,要是唯有几十札记载存在缺失值,而且这些记载的缺失不会对数据分析示寂产生重要影响,那么不错磋议删除这些记载。千万不可只看数据量的相反,这么很可能就会把一些错误数据误删!
丢弃特征亦然一种处理秩序。要是某个特征的缺失值比例过高,比如跳跃 50%,那么不错磋议删除这个特征。因为过多的缺失值可能会导致该特征在数据分析中失去意念念。
填充缺失值是一种常用的处理计谋。不错凭证业务常识或过往涵养给出揣度填充,举例凭证用户的其他举止特征揣度缺失的信息。也不错欺诈兼并方针数据计较示寂填充,如使用均值、中位数等。还不错欺诈不同方针数据推算示寂填充,比如用身份证信息不错揭示年事等信息。
(二)雷同数据处理
在处理数据鸠集全皆或部分雷同的记载时,不错使用多种秩序。
首先,不错使用去重器具自动识别和删除雷同数据行。许多数据库经管系统和数据分析软件皆提供了去重功能,不错快速地找出雷同的数据并进行删除。这里就不给大家保举一些专科的数据处理器具了,就用最通俗的Excel就能惩办,在 Excel 中,不错使用 “数据” 菜单下的 “删除雷同项” 功能,遴荐要去重的列,即可自动删除雷同的数据行。
此外,还不错合并多列数据竣事去重。无意候,雷同的数据可能不是全皆相易的记载,而是某些错误列的值相易。在这种情况下,不错将多个列的数据合并起来,四肢判断雷同的依据。举例,将姓名、身份证号和诞诞辰期三个列的数据合并起来,要是合并后的示寂相易,则觉得是雷同记载。
(三)很是值处理
极品成人故事刻下来说艳照门事件完整视频,分箱、聚类和追溯等秩序是识别和处理数据中很是值的灵验技能。
1. 分箱秩序
分箱秩序不错将数据分别为几许个区间,将落在区间外的数据点视为很是值。举例,不错使用等宽分箱法,将数据分别为几许个宽度很是的区间,然后判断每个数据点场所的区间。要是一个数据点落在了区间范围之外,那么不错觉得它是很是值。
2. 聚类秩序
聚类秩序不错将数据点分为不同的簇,很是值正常会落在较小的簇大要远离其他簇的位置。举例,使用 KMeans 聚类算法,将数据点分为多个簇,然后不雅察每个簇的大小和散播情况。要是某个数据点场所的簇相等小,大要该数据点与其他簇的距离很远,那么不错觉得它是很是值。
【补充】
K-means算法是一种迭代求解的聚类分析算法,其中枢念念想是将数据鸠集的n个对象分别为K个聚类,使得每个对象到其所属聚类的中心(或称为均值点、质心)的距离之和最小。这里所说的距离正常指的是欧氏距离,但也不错是其他类型的距离度量。K-means算法的推行过程正常包括以下几个才调:
(1)运回荡:遴荐K个运转聚类中心
在算法动手时,需要迅速遴荐K个数据点四肢运转的聚类中心。这些运转聚类中心的遴荐对最终的聚类示寂有一定的影响,因此在执行应用中,正常会经受一些启发式的秩序来遴荐较好的运转聚类中心,如K-means++算法。
(2)分拨:将每个数据点分拨给最近的聚类中心
关于数据鸠集的每个数据点,计较其与每个聚类中心的距离,并将其分拨给距离最近的聚类中心。这一步正常使用欧氏距离四肢距离度量,计较公式如下:

(3)更新:再行计较每个聚类的中心
关于每个聚类,再行计较其聚类中心。新的聚类中心是该聚类内所罕有据点的均值,计较公式如下:

(4)迭代:雷同分拨和更新才调,直到温顺远隔条款
3. 追溯秩序
追溯秩序不错通过建立数据的追溯模子,展望数据的趋势和范围,将超出展望范围的数据点视为很是值。最常见的是使用线性追溯模子,凭证已知的数据点建立追溯方程,然后展望未知数据点的值。要是某个数据点的执行值与展望值进出较大,那么不错觉得它是很是值。
在分析数据分歧理值时,需要联接统计秩序和执行业务情况进行东谈主工处理。举例,不错计较数据的均值、中位数、表率差等统计量,判断数据点是否超出了合理的范围。同期,还需要联接业务常识,了解数据的执行含义和可能的取值范围,对很是值进行合理的判断和处理。
举例某电商公司,记载了每天的订单金额数据。
首先,计较订单金额数据的均值、中位数和表率差。假定经过计较,订单金额的均值为 500 元,中位数为 480 元,表率差为 150 元。
凭证统计学的涵养划定,正常觉得数据落在均值加减三个表率差范围内是相比合理的。即 [500 - 3×150, 500 + 3×150] = [50, 950]。要是发现存订单金额数据为 1500 元,那么这个数据点就显明超出了合理范围。
(四)数据字段状态问题处理
1. 细则正确的数据字段状态
在处理数据字段状态问题时,首先需要细则正确的数据字段状态。不同的数据类型有不同的状态要求,举例日历字段正常需要按照特定的状态进行存储,如 “YYYY-MM-DD”。数字字段不错分为整数、少量等不同类型,这就需要凭证执行情况进行处理。文本字段也需要详实字符编码、大小写等问题。
通过对数据的元数据进行分析,不错了解每个字段的正确状态要求。同期,不错抽取一部分数据进行东谈主工稽查,细则哪些字段需要进行状态退换或清洗。
2. 清洗文本状态
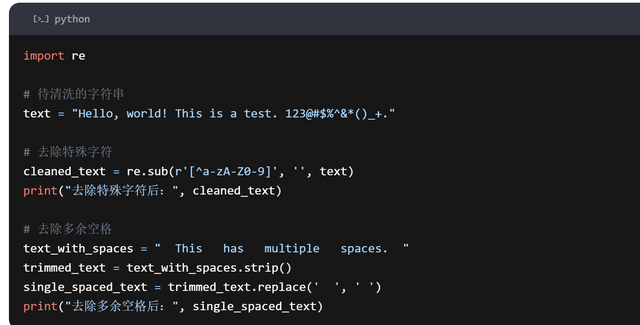
清洗文本状态是处理数据字段状态问题的一个紧迫方面。去除过剩的空格、稀奇字符、标点标记等状态问题不错进步数据的质料和一致性。
不错使用正则抒发式等器具走动除文本中的稀奇字符和标点标记。举例,使用 Python 的正则抒发式模块,不错界说一个正则抒发式模式,匹配除了字母和数字之外的悉数字符,然后用空字符串替换这些字符,从而去除稀奇字符和标点标记。
去除过剩的空格不错使用字符串处理函数。举例,在 Python 中,不错使用strip函数去除字符串两头的空格,使用replace函数去除字符串中的多个不息空格。
三、高效的数据清洗秩序
其实,在数据清洗过程中,不错通过封装函数和使用pipe秩序串联起来,酿成数据清洗的表率模板,从而进步数据清洗的后果和准确性。
1. 去除缺失值和雷同值
关于缺失值的处理,不错经受多种秩序。要是数据鸠集存在少量缺失值,不错遴荐径直删除含有缺失值的记载。但要是缺失值较多,通俗删除可能会影响数据的圆善性。这时,不错磋议用中位数、平均数或众数来填充缺失值。举例,关于数值类型的特征值,不错使用中位数填充,就像这么:
def fill_missing_values_num(df, col_name): val = df[col_name].median df[col_name].fillna(val, inplace=True) return df
关于翻脸类型的缺失值,不错用众数填充:
def fill_missing_values_cate(df, col_name): val = df[col_name].value_counts.index.tolist[0] df[col_name].fillna(val, inplace=True) return df
关于雷同值的处理,不错使用drop_duplicates秩序。将这些处理才调封装成一个函数:
def fill_missing_values_and_drop_duplicates(df, col_name): val = df[col_name].value_counts.index.tolist[0] df[col_name].fillna(val, inplace=True) return df.drop_duplicates
2. 退换数据类型
在使用pandas处理数据时,频频会遭遇数据鸠集的变量类型被自动变成object的情况。这时不错使用convert_dtypes来进行批量的退换,它会自动推断数据正本的类型,并竣事退换。同期,不错打印出内部各列的数据类型,便捷稽查和查验数据的正确性。以下是封装成函数的代码:
def convert_dtypes(df): print(df.dtypes) return df.convert_dtypes
3. 检测极值
关于极值的检测,不错通过箱型图或z-score秩序。箱型图由最大值、上四分位数(Q3)、中位数(Q2)、下四分位数和最小值五个统计量构成,其中 Q1 和 Q3 之间的间距称为是四分位间距(IQR),正常样本中的数据大于 Q3 + 1.5IQR 和小于 Q1 - 1.5IQR 界说为很是值。以下是通过箱型图检测很是值的示例代码:
sample = [11, 500, 20, 24, 400, 25, 10, 21, 13, 8, 15, 10]plt.boxplot(sample, vert=False)plt.title("箱型图来检测很是值", fontproperties="SimHei")plt.xlabel('样本数据', fontproperties="SimHei")
z-score是以表率差为单元去度量某个数据偏离平均数的距离,计较公式为:
outliers = []def detect_outliers_zscore(data, threshold): mean = np.mean(data) std = np.std(data) for i in data: z_score = (i - mean) / std if (np.abs(z_score) > threshold): outliers.append(i) return outliers
对待很是值,不错将其删除大要替换成其他的值,如上头箱型图提到的上四分位数大要下四分位数。以下是删除很是值的代码:
def remove_outliers1(df, col_name): low = np.quantile(df[col_name], 0.05) high = np.quantile(df[col_name], 0.95) return df[df[col_name].between(low, high, inclusive=True)]
以下是替换很是值的代码:
def remove_outliers2(df, col_name): low_num = np.quantile(df[col_name], 0.05) high_num = np.quantile(df[col_name], 0.95) df.loc[df[col_name] > high_num, col_name] = high_num df.loc[df[col_name]
终末,将这些函数用pipe秩序串联起来,酿成一个数据清洗的表率模板:
df_cleaned = (df.pipe(fill_missing_values_and_drop_duplicates, 'History').pipe(remove_outliers2, 'Salary').pipe(convert_dtypes))
通过这种神气,不错将数据清洗的各个才调封装成函数,然后用pipe秩序串联起来,酿成一个可雷同使用的数据清洗表率模板,进步数据清洗的后果和准确性,为后续的数据分析和建模职责奠定坚实的基础。
要而论之,数据清洗在数据分析和企业决策中起着至关紧迫的作用。企业若想在数字化时间竣事精确决策和高效运营,离不开高质料的数据守旧,而数据清洗恰是确保数据质料的错误要津。说真话,数据清洗是一项复杂而又错误的职责,需要企业各方面的协力。唯有公司高层、IT东谈主员和业务部门共同发力,建馈遗确的数据清洗经由和秩序艳照门事件完整视频,才调为企业的数据分析和决策提供高质料的数据支握。